BigID API/Duplicate Data Tutorial: Difference between revisions
No edit summary |
|||
| (11 intermediate revisions by one other user not shown) | |||
| Line 2: | Line 2: | ||
In this article, you'll learn: | In this article, you'll learn: | ||
* What the BigID data catalog can be used for | * What the BigID data catalog can be used for | ||
* | * How to use the has_duplicates filter | ||
* | * How to use the duplicate_id filter | ||
{{Box/end}} | {{Box/end}} | ||
| Line 9: | Line 9: | ||
{{Scenario|You're seeing increasingly high storage costs in your cloud data sources. Looking at the names of these data sources, they don't seem to be storing anything that's particularly large, but you suspect that they're storing similar data which is increasing your storage costs. '''Use the BigID catalog to get a list of duplicated data'''}} | {{Scenario|You're seeing increasingly high storage costs in your cloud data sources. Looking at the names of these data sources, they don't seem to be storing anything that's particularly large, but you suspect that they're storing similar data which is increasing your storage costs. '''Use the BigID catalog to get a list of duplicated data'''}} | ||
{{:InformationTemplates:BigID_Catalog}} | |||
This means that both structured and unstructured data sources can have multiple objects within them. In a production BigID system there can be millions of objects so we need to filter. {{Note|If you ever want to request information about objects with specific properties think: What filter should I use?}} | |||
== Using Duplicate Filters == | |||
Let's use the has_duplicates filter to request objects that contain duplicate files. | |||
<html> | <html> | ||
<iframe style="border:0px; width:100%; height:400px; border-radius:10px;" src="https:// | <iframe style="border:0px; width:100%; height:400px; border-radius:10px;" src="https://apiexplorer.bigid.tools/?url=data-catalog%3Ffilter%3Dhas_duplicates%3D%22true%22&method=GET&headers=%5B%7B%22name%22%3A%22Authorization%22%2C%22value%22%3A%22SAMPLE%22%7D%5D"></iframe> | ||
</html> | </html> | ||
This second API call only returns around 47 results as opposed to the around 100 results returned from the previous request. But what are the duplicates? Each duplicate object has a duplicate_id that represents a hash of the file. We can filter objects by this ID to find all the duplicates. '''Replace DUPLICATEID in the URL of the request below with the duplicate_id of the first object above to find its duplicates.''' | |||
<syntaxhighlight lang=" | <html> | ||
{ | <iframe style="border:0px; width:100%; height:400px; border-radius:10px;" src="https://apiexplorer.bigid.tools/?url=data-catalog%3Ffilter%3Dduplicate_id%3D%22DUPLICATEID%22&method=GET&headers=%5B%7B%22name%22%3A%22Authorization%22%2C%22value%22%3A%22SAMPLE%22%7D%5D"></iframe> | ||
" | </html> | ||
" | |||
" | Now you have a list of the files that are duplicated, you can delete some of your unneeded copies to save on data storage costs. | ||
" | |||
== Code Samples == | |||
<tabs> | |||
<tab name="Python"><syntaxhighlight lang="python" line> | |||
# Duplicate Data Tutorial | |||
import requests | |||
import json | |||
base_url = "https://developer.bigid.com/api/v1" | |||
headers = { | |||
"Authorization": "Bearer SAMPLE", | |||
"Content-Type": "application/json" | |||
} | |||
# 1. Get all catalog objects | |||
response = requests.get( | |||
f"{base_url}/data-catalog", | |||
headers=headers | |||
) | |||
data = response.json() | |||
print("All Objects:", json.dumps(data, indent=2)) | |||
# 2. Get catalog objects that have duplicates | |||
response = requests.get( | |||
f"{base_url}/data-catalog?filter=has_duplicates=\"true\"", | |||
headers=headers | |||
) | |||
data = response.json() | |||
print("Duplicate Objects:", json.dumps(data, indent=2)) | |||
# Get the duplicate_id of the first object (for example) | |||
results = data.get("results", []) | |||
first_object = results[0] | |||
duplicate_id = first_object.get("duplicate_id") | |||
# 3. Get all objects that share the same duplicate_id | |||
response = requests.get( | |||
f"{base_url}/data-catalog?filter=duplicate_id=\"{duplicate_id}\"", | |||
headers=headers | |||
) | |||
data = response.json() | |||
print("Objects with same duplicate_id:", json.dumps(data, indent=2)) | |||
</syntaxhighlight></tab> | |||
<tab name="JavaScript"><syntaxhighlight lang="javascript" line> | |||
// Duplicate Data Tutorial | |||
const baseUrl = "https://developer.bigid.com/api/v1"; | |||
const headers = { | |||
"Authorization": "Bearer SAMPLE", | |||
"Content-Type": "application/json" | |||
}; | |||
// 1. Get all catalog objects | |||
async function getAllCatalogObjects() { | |||
console.log("Fetching all catalog objects..."); | |||
const res = await fetch(`${baseUrl}/data-catalog`, { headers }); | |||
const data = await res.json(); | |||
console.log("All Objects:", JSON.stringify(data, null, 2)); | |||
return data; | |||
} | |||
// 2. Get catalog objects that have duplicates | |||
async function getObjectsWithDuplicates() { | |||
console.log("Fetching objects with duplicates..."); | |||
const res = await fetch(`${baseUrl}/data-catalog?filter=has_duplicates="true"`, { headers }); | |||
const data = await res.json(); | |||
console.log("Duplicate Objects:", JSON.stringify(data, null, 2)); | |||
return data; | |||
} | |||
// 3. Get all objects that share the same duplicate_id | |||
async function getObjectsByDuplicateId(duplicateId) { // Use duplicate id of desired object obtained above in step 2 | |||
console.log(`Fetching objects for duplicate_id: ${duplicateId}`); | |||
const res = await fetch(`${baseUrl}/data-catalog?filter=duplicate_id="${duplicateId}"`, { headers }); | |||
const data = await res.json(); | |||
console.log("Objects with same duplicate_id:", JSON.stringify(data, null, 2)); | |||
return data; | |||
} | |||
</syntaxhighlight> | </syntaxhighlight> | ||
</tab> | |||
</tabs> | |||
<html> | |||
<style> | |||
.tabs-tabbox > .tabs-container { | |||
margin-top: -1px; | |||
padding: | |||
2px 6px; | |||
border-radius: | |||
8px; | |||
position: relative; | |||
border: | |||
2px solid #848484; | |||
width: inherit; | |||
max-width: inherit; | |||
min-width: inherit; | |||
box-shadow: | |||
0px 4px 6px 1px rgba(0, 0, 0, 0.1); | |||
z-index: 1; | |||
} | |||
.tabs-tabbox > .tabs-label { | |||
margin: | |||
0 3px; | |||
border-bottom: | |||
none; | |||
border-radius: | |||
4px 4px 0 0; | |||
position: relative; | |||
display: inline-block; | |||
vertical-align: bottom; | |||
padding-left: 10px; | |||
padding-right: 10px; | |||
padding-bottom: 3px; | |||
padding-top: 3px; | |||
} | |||
.tabs-tabbox > .tabs-input:checked + .tabs-label, .tabs-input-0:checked + .tabs-input-1 + .tabs-label { | |||
background-color: #0e69b2 !important; | |||
border-color: | |||
#848484; | |||
z-index: 0; | |||
color: white; | |||
} | |||
.tabs-label { | |||
cursor: pointer; | |||
border: | |||
2px solid #848484; | |||
} | |||
.mw-body .tabs-label { | |||
{ | background-color: #ffffff26; | ||
} | } | ||
</ | </style> | ||
</html> | |||
[[Category:Tutorial]][[Category:API]] | |||
Latest revision as of 15:23, 17 June 2025
- What the BigID data catalog can be used for
- How to use the has_duplicates filter
- How to use the duplicate_id filter
The BigID Catalog
The BigID catalog provides a view into all of your data. It allows you to see the types of data being held in each column, the access rights for that data and how it relates to other information across your systems. Below is a demo of the catalog through the BigID UI:
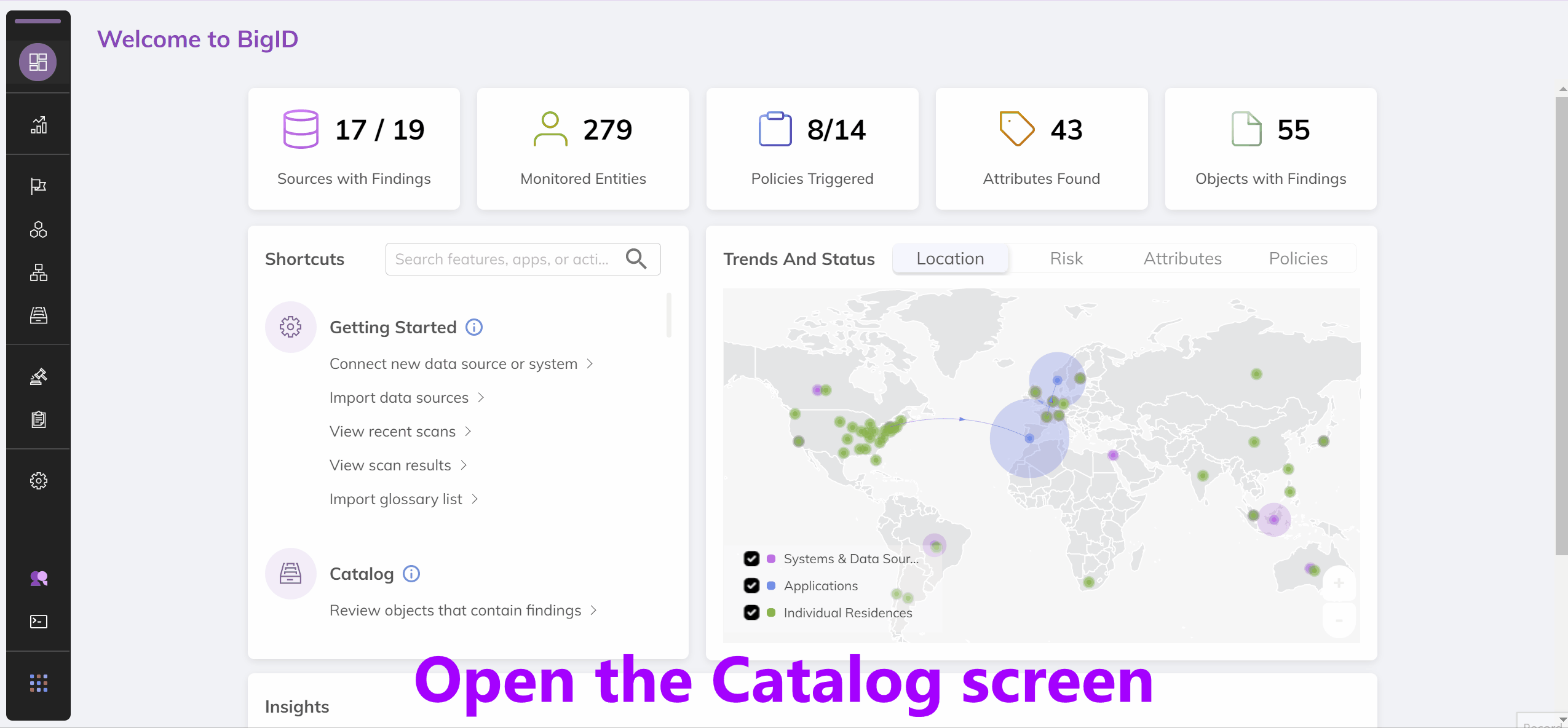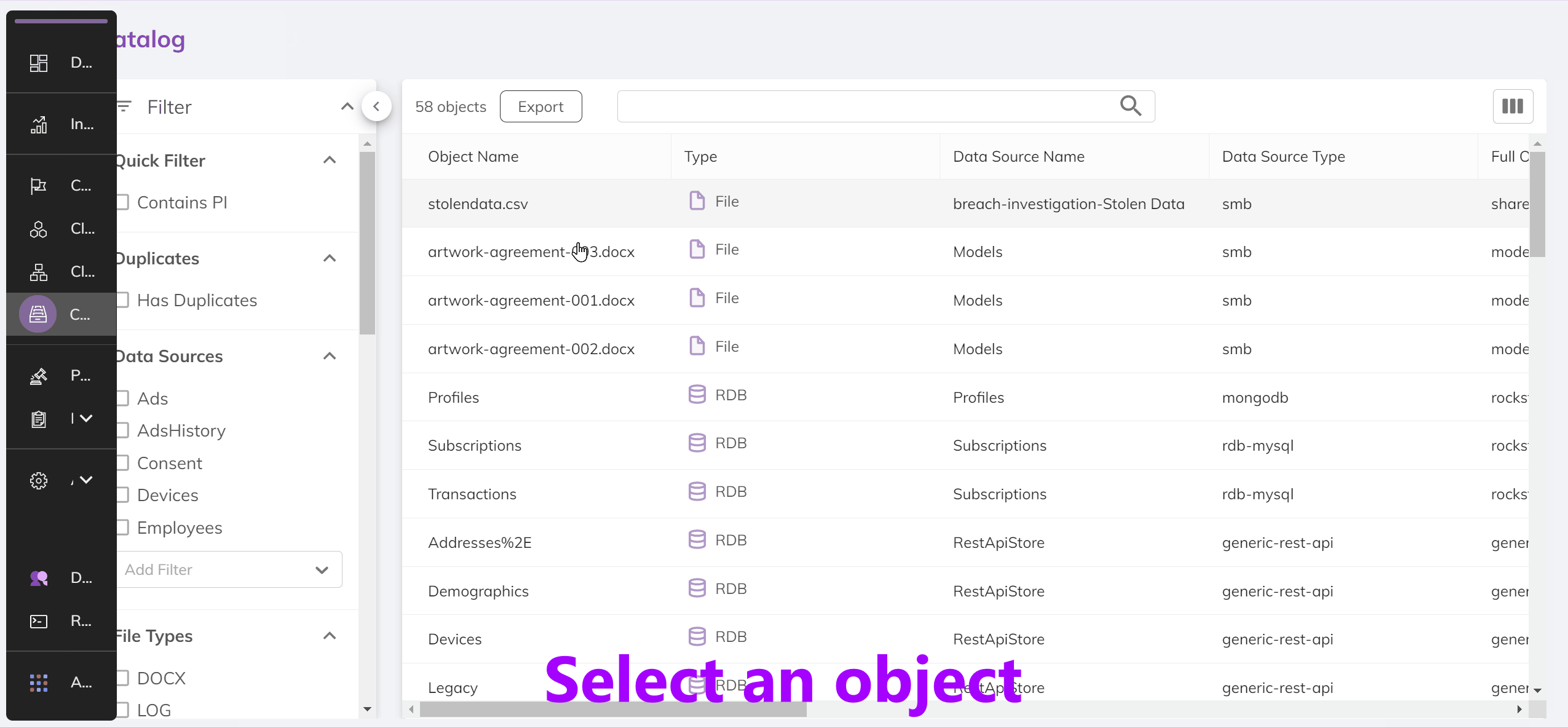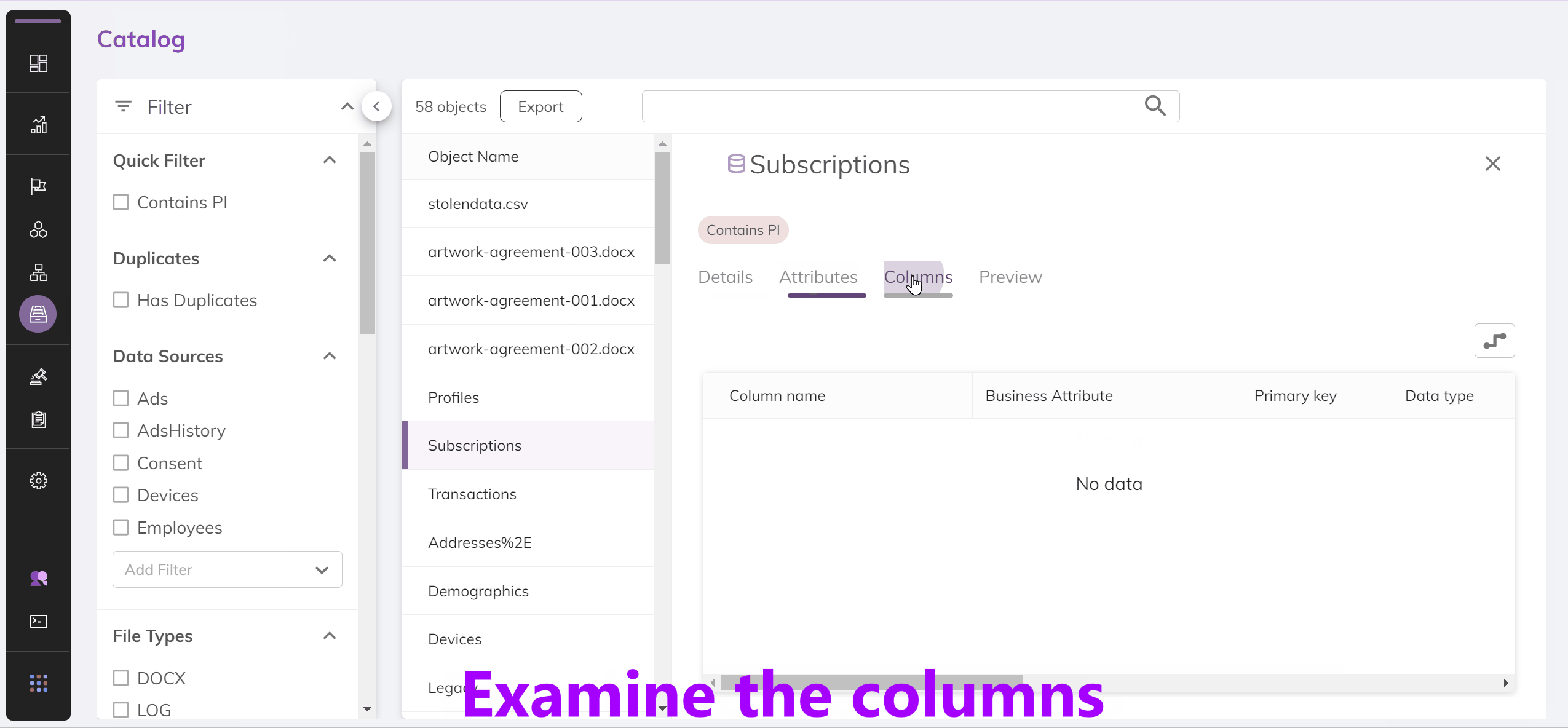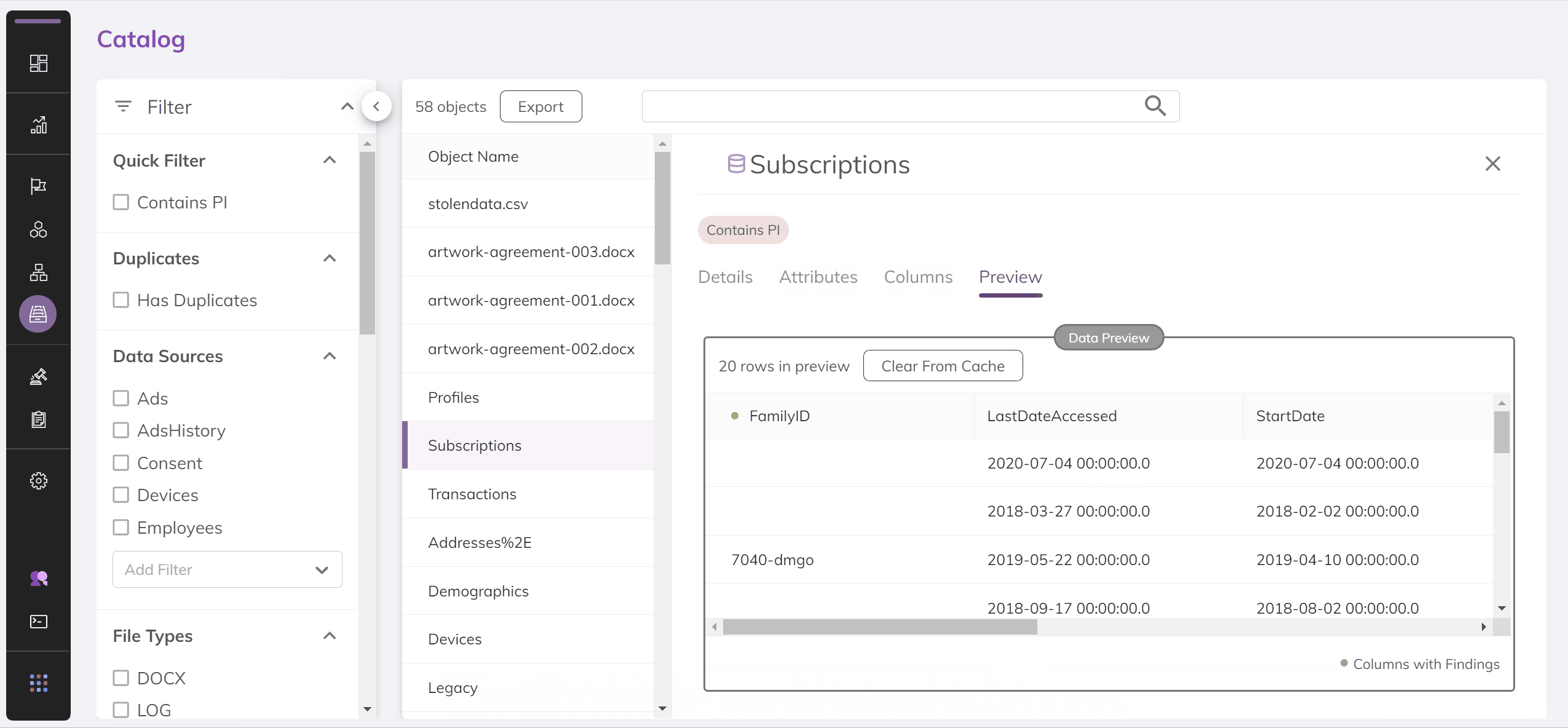
Since we care about the data within the API as opposed to the UI, let's see what the API response that powers this page looks like.
In the results section of the response you'll see a listing much like that in the UI. Each of these items is an object. An object is:
- A database table in a structured data source
- A file in an unstructured data source
This means that both structured and unstructured data sources can have multiple objects within them. In a production BigID system there can be millions of objects so we need to filter.
Using Duplicate Filters
Let's use the has_duplicates filter to request objects that contain duplicate files.
This second API call only returns around 47 results as opposed to the around 100 results returned from the previous request. But what are the duplicates? Each duplicate object has a duplicate_id that represents a hash of the file. We can filter objects by this ID to find all the duplicates. Replace DUPLICATEID in the URL of the request below with the duplicate_id of the first object above to find its duplicates.
Now you have a list of the files that are duplicated, you can delete some of your unneeded copies to save on data storage costs.
Code Samples
# Duplicate Data Tutorial
import requests
import json
base_url = "https://developer.bigid.com/api/v1"
headers = {
"Authorization": "Bearer SAMPLE",
"Content-Type": "application/json"
}
# 1. Get all catalog objects
response = requests.get(
f"{base_url}/data-catalog",
headers=headers
)
data = response.json()
print("All Objects:", json.dumps(data, indent=2))
# 2. Get catalog objects that have duplicates
response = requests.get(
f"{base_url}/data-catalog?filter=has_duplicates=\"true\"",
headers=headers
)
data = response.json()
print("Duplicate Objects:", json.dumps(data, indent=2))
# Get the duplicate_id of the first object (for example)
results = data.get("results", [])
first_object = results[0]
duplicate_id = first_object.get("duplicate_id")
# 3. Get all objects that share the same duplicate_id
response = requests.get(
f"{base_url}/data-catalog?filter=duplicate_id=\"{duplicate_id}\"",
headers=headers
)
data = response.json()
print("Objects with same duplicate_id:", json.dumps(data, indent=2))
// Duplicate Data Tutorial
const baseUrl = "https://developer.bigid.com/api/v1";
const headers = {
"Authorization": "Bearer SAMPLE",
"Content-Type": "application/json"
};
// 1. Get all catalog objects
async function getAllCatalogObjects() {
console.log("Fetching all catalog objects...");
const res = await fetch(`${baseUrl}/data-catalog`, { headers });
const data = await res.json();
console.log("All Objects:", JSON.stringify(data, null, 2));
return data;
}
// 2. Get catalog objects that have duplicates
async function getObjectsWithDuplicates() {
console.log("Fetching objects with duplicates...");
const res = await fetch(`${baseUrl}/data-catalog?filter=has_duplicates="true"`, { headers });
const data = await res.json();
console.log("Duplicate Objects:", JSON.stringify(data, null, 2));
return data;
}
// 3. Get all objects that share the same duplicate_id
async function getObjectsByDuplicateId(duplicateId) { // Use duplicate id of desired object obtained above in step 2
console.log(`Fetching objects for duplicate_id: ${duplicateId}`);
const res = await fetch(`${baseUrl}/data-catalog?filter=duplicate_id="${duplicateId}"`, { headers });
const data = await res.json();
console.log("Objects with same duplicate_id:", JSON.stringify(data, null, 2));
return data;
}