BigID API/Duplicate Data Tutorial: Difference between revisions
| Line 21: | Line 21: | ||
</html> | </html> | ||
In the response | In the results section of the response you'll see a listing much like that in the UI. Each of these items is an object. An object is: | ||
* A database table in a structured data source | |||
* A file in an unstructured data source | |||
< | This means that both structured and unstructured data sources can have multiple objects within them. In a production BigID system there can be millions of objects so we need to filter. Let's just request objects that contain duplicate data. | ||
<html> | |||
<iframe style="border:0px; width:100%; height:400px; border-radius:10px;" src="https://apibrowser.mybigid.com/?url=data-catalog%3Fhas_duplicates%3D%22true%22method=GET&headers=%5B%7B%22name%22%3A%22Authorization%22%2C%22value%22%3A%22SAMPLE%22%7D%5D"></iframe> | |||
</html> | |||
</ | |||
== Calling an API == | == Calling an API == | ||
Revision as of 20:09, 5 November 2021
- What the BigID data catalog can be used for
- Retrieving object data from the catalog via API
- Retrieving column data from the catalog via API
The BigID Catalog
The BigID catalog provides a view into all of your data. It allows you to see the types of data being held in each column, the access rights for that data and how it relates to other information across your systems. Below is a demo of the catalog through the BigID UI:
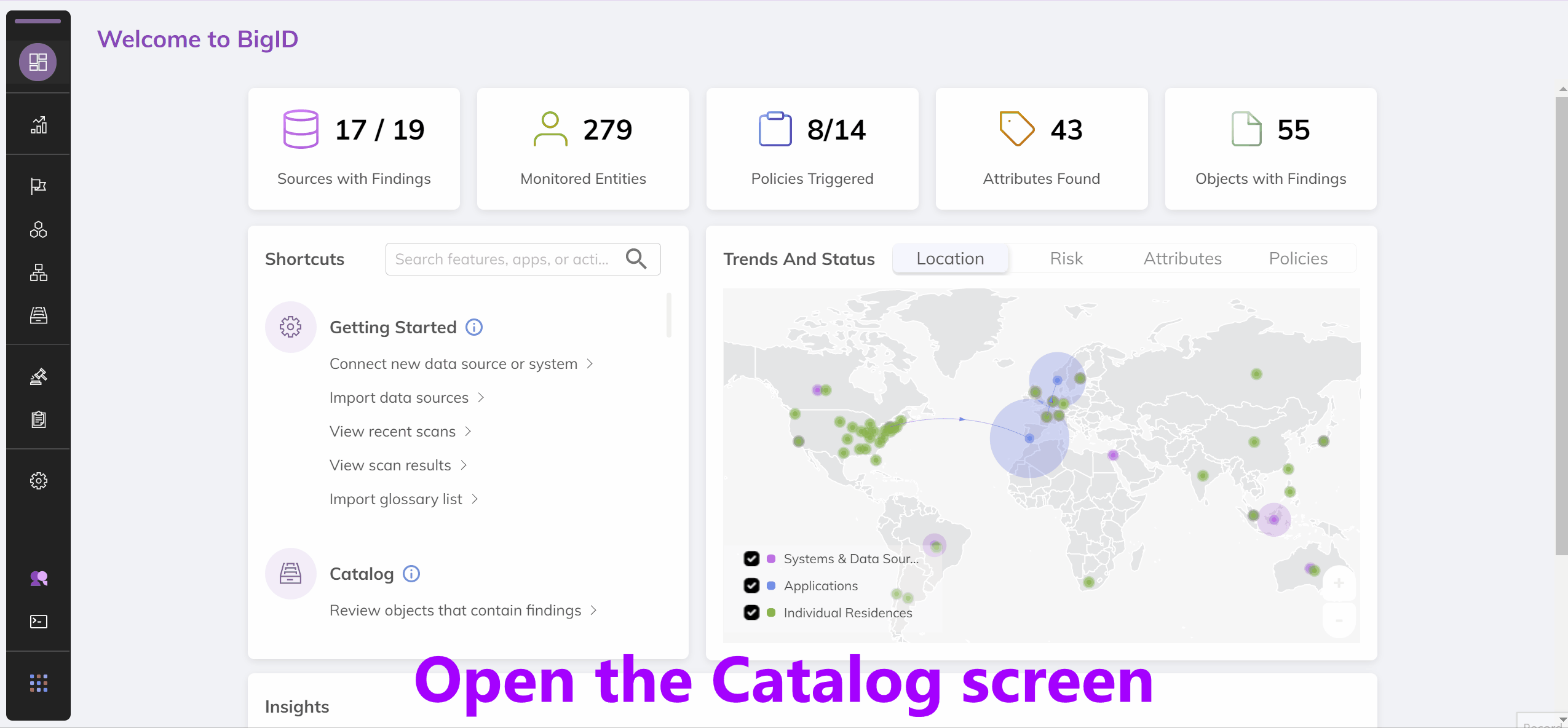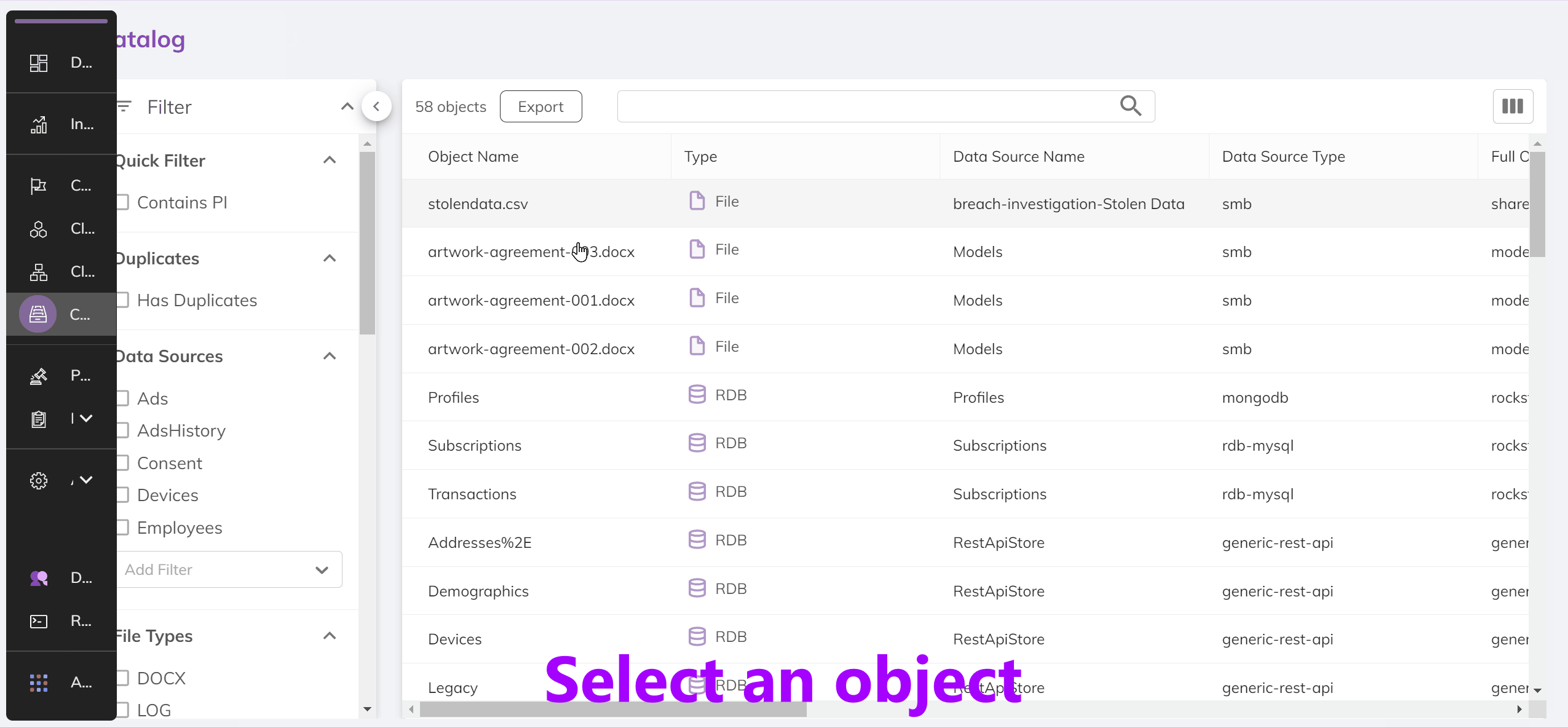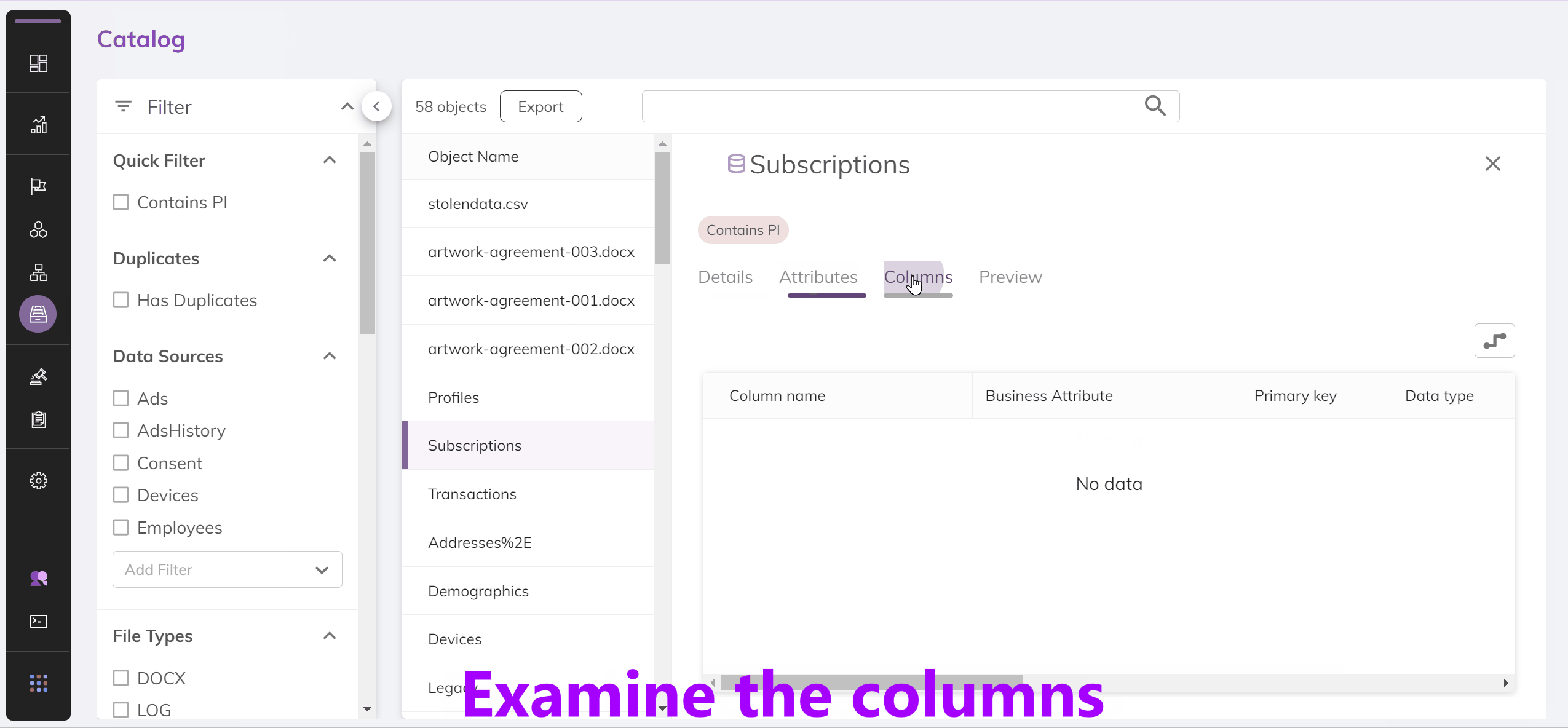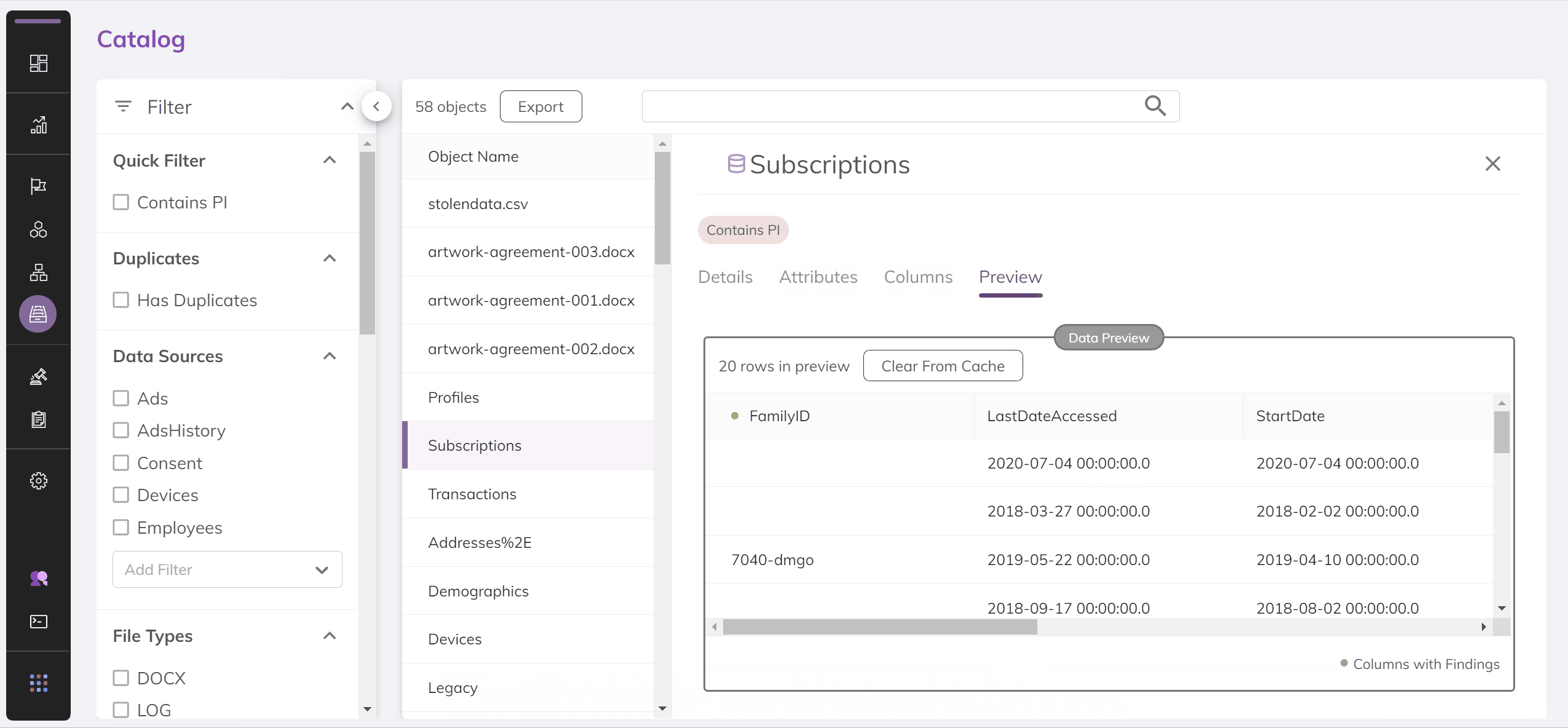
Since we care about the data within the API as opposed to the UI, let's see what the API response that powers this page looks like.
In the results section of the response you'll see a listing much like that in the UI. Each of these items is an object. An object is:
- A database table in a structured data source
- A file in an unstructured data source
This means that both structured and unstructured data sources can have multiple objects within them. In a production BigID system there can be millions of objects so we need to filter. Let's just request objects that contain duplicate data.
Calling an API
Now that you have a session token we can directly call BigID APIs. Documentation for these APIs is available at https://www.docs.bigid.com/bigid/reference/api-getting-started . Since we're just trying to perform a simple task, we don't need the docs here, just to know that GET /ds-connections is the endpoint to retrieve a list of data source connections.
Add a new header named "Authorization" and paste the session token you got in the previous request to authenticate yourself.
In that API call, we can see a list of data sources and all the information for each data source.
{
"status": "success",
"statusCode": 200,
"data": {
"ds_connections": [
"<data source info here>"
]
}
}